- The Cerberus Project
- Introduction
- 1. Chapter 0 - Pitch and Abstract
- 2. Chapter 1 - Pitch and Summer Work
- 3. Chapter 2 - Fall 2014 Work
- 4. Chapter 3 - Spring 2015 Work
- 5. Chapter 4 - Architecture Software, Dependencies and Provisioning
- 6. Chapter 5 - Current Hardware Configurations
- 7. Chapter 6 - Monitoring the Cluster
- 8. Chapter 7 - Current Limitations of the Project
- 9. Chapter 8 - Utilizing the Cerberus Program
- 10. Chapter 9 - Performance of the Project
- 11. Chapter 10 - Final Results and Special Thanks
Chapter 4.1:
Architecture Software:
This project is entirely dependent on a wide variety of software tools, published and unpublished. Due to the open-source nature of the Linux operating system, as well as its intense catering to developers; it is the perfect operating system to be used. UNIX type operating systems exist on the 'building blocks' mentality, ie. a combination of small tools, being used to collaboratively accomplish the final goal rather than a wide variety of complex tools that serve a single purpose. This exemplifies why Linux is a preferred operating system for this project; it allows for flexibility and optimization by only utilizing the tools chosen with minimal computational overhead.
Operating System - CentOS
CentOS is a particularly useful distribution of the Linux operating system environment. Short for Community Enterprise Operating System, CentOS is an enterprise, lightweight Linux distribution that caters to the needs of development heavy software ecosystems. CentOS is based on the RHEL (Red Hat Enterprise Linux) kernel and package managers. This incorporates all of the engineering and security / enterprise features that RHEL users have access to, but in a free distribution. Cent is still developed with Long Term Stability releases (LTS) in mind which makes is optimal for the project
![]()
CentOS draws from the RPM software package management environment, utilizing the Yum package manager. RPM is short for 'RedHat Package Manager' which means that CentOS users have access to all of the enterprise standardized software packages that the RHEL platform is developed for. In addition to this, EPEL (Extra Packages for Enterprise Linux) and REMI repository package selections can also be added, which allows for the installation of supported GNU/GPL software tools. This project takes advantage of EPEL with REMI support disabled. Custom repositories are also generated but those will be covered later because they are non-standard with CentOS.
CentOS 6.5 and 6.6 are the current supported software versions as supported by the project. Although CentOS Version 7 was released shortly after the passing of the proposal of this thesis, it was disavowed from potential use here due to its beta like state. CentOS 7 is a finished project but CentOS 6.5 and 6.6 are both still supported under LTS release for many years to come and are known to be bug free in a wide variety of arenas, all of which are required to be stable and efficient for the project to perform well.
CentOS incorporates a valuable software tool known as the Anaconda installer. Often known as a 'kick starter', Anaconda allows a large volumes of machines to all be imaged or freshly installed from a kick start script. This means that Cent can be installed via one of these scripts with little user input, which is the first step in autonomous node addition to the cluster. A valuable kickstart script has been been generated and used widespread and is held in the internal documentation.
This script installs the correct architecture release of CentOS 6.6 on nodes while configuring networking, internal drive structures and firewalls and user account creation. From here, other software takes over to finish provisioning new nodes. Currently, provisioning a node takes just under an hour. Networking is dependent on the speed at which RIT RESNET works. In order to finish provisioning the nodes, networking is required, which requires proper registration onto the RIT network. This can take minutes or hours, and is purely at the mercy of the operating speed of RIT RESNET's student employees. Which can be a small eternity.
Software Provisioning - Ansible
Ansible is an excellent provisioning tool, similar to Salt and Puppet. Unlike the others, however, Ansible provisions over SSH which makes it fast and powerful to use. Once nodes are established on the network, they can be added to the Ansible hosts playbook, stored on the Head node and backup up to a repository. From here, the Head node can provision any other connected node, simultaneously.

One of Ansible's best features is its dual functionality. Ansible can either be utilized to run a command, ad-hoc, across an array of nodes from contained headers in the host file, or it can be used to run a specialized YAML syntax playbook which is used to execute a list of commands in order of specification across pre-designated clusters or groups. The first, ad-hoc method, is especially helpful for mass-testing or to simply perform basic tasks across nodes in an elegant manner. This is useful for Yum update operations or modifying the iptables of a series of nodes where it is easier to run a simple ad-hoc command rather than build a playbook for single use operations. The second is the most powerful feature of Ansible, because it is the backbone of elegant provisioning. Ansible allows for a hierarchical Playbook to be constructed. This playbook is formatted for YAML syntax, and acts like a complex to-do list. Modules and sub-modules can be defined and referenced in each playbook with advanced support for error handling and reporting.
Ansible is available free and open-source in its command line state. There are other, additional, enterprise and professional features like Graphical UI's, monitoring and alerting sent from a Proprietary application platform known as Ansible Tower, but this was entirely unnecessary for the project. Ansible also offers enterprise support, but that was deemed unnecessary as well. Ansible is already incredibly easy to implement based on the command line, and can be installed via a simple Yum install argument so long as the dependencies are met. The dependencies are conveniently installed as part of the CentOS kickstart script, which means that installing Ansible is no problem. Ansible also works on both 32 and 64-bit architectures which makes it compatible with the entire cluster.
Benchmarking
Benchmarking an entire cluster comes with the responsibility of monitoring and performance testing a massive array of system variables. This process is intensely valuable to the progress of the project because the project relies on the cooperative power of a variety of machines. In order to gauge the effectiveness of these machine, there must be some quantitative, qualitative or arbitrary baseline by which to compare all machines. Machines that exceed or score a certain Currently, there are three phases to the benchmark process. One of these phases was removed early on, but will still be covered (albeit briefly) due to the time intensive nature it took to install and configure.
Homebrew Shell Benchmarking
Initially, the construction of an entirely custom benchmarking suite was envisioned. This led to a massive programming campaign that ended with several rudimentary tools being developed and configured to run on the cluster. This basic suite tested disk write speed and the speed at which the network could copy files via SCP. The results were then piped through shell programming to be stored on a centralized server. Another shell script parsed the information and removed the relevant information to be plotted via a service like Excel or MATLAB. A shell script running from the head node was implemented to run each of these processes on each attached node, which was inefficient and introduced before Ansible was implemented.
Eventually, this form of benchmarking was discontinued because it required a tireless amount of manual data analysis that grew exponentially in order to simply visualize the performance of each unit. The method was not efficient and provided no elegant output. As a result, although massive time was devoted for several weeks to home brew this suite, it was scrapped. Time earmarked for future development was devoted to finding open-source benchmark suites that scaled easily and generated elegant outputs in order to grant quick analytic.
Phoronix Test Suite
After searching, a viable benchmarking suite was discovered and implemented across the cluster. Phoronix is an open-source variable test benchmarking suite. Phororonix manages a massive library of tests, arranged by individual test names and custom generated test suites. These test suites contain groupings of individual tests that cater to a specific facet of a system to test (ie CPU, RAM or Disk I/O) or an array of tests chosen to test the entire holistic performance of a system. Phoronix shines, in respect, to the fact that one of the included tests tests the limits and functionality of dc.RAW - one of the key software components of the cluster.
Phoronix tests come with defaults but based on the engineering of the software test packages, and one of these benchmarking tools can be modified. As of the end of Fall semester, modifying the dc.RAW test is underway and expected to carry into intersession, the academic period between Fall and Spring semester.
Geekbench 3
While PTS (Phoronix Test Suite) was a massive help in individual test benchmarking, it still did not provide an elegant approach to holistically testing the performance of systems. As a result of this, a third, and final, service was discovered. Geekbench is a proprietary software testing suite that came with massive power at a reasonable price point. Geekbench tests aver 100 facets of the test system in less than 30 minutes and quantifies the results against a reasonable baseline.

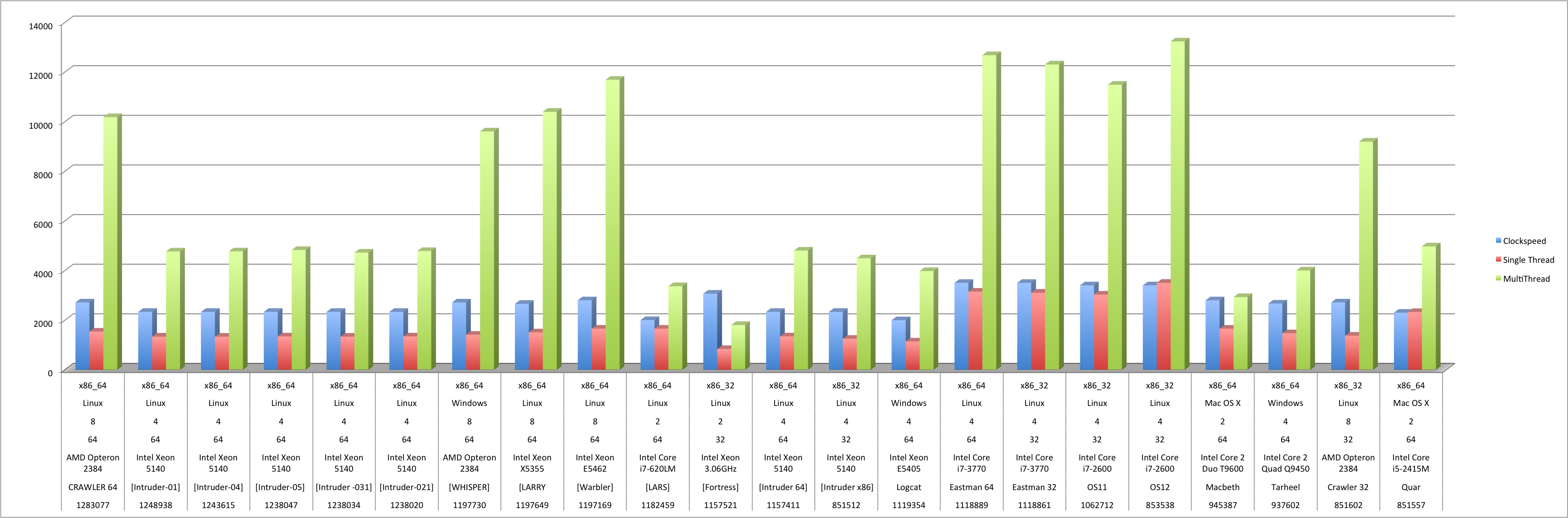
Licensing Geekbench 3 is a lifetime affair and has no limitations to the quantity of tests that can be run. This makes it ideal for a growing cluster. Within the Geekbench branded web dashboard, any two systems can be compared to see where one excels against the other, in any specific category. GB3 also combines all of these scores and averages them internally to generate an arbitrary ranking comprised of two numbers. The first is a comprehensive score of single core performance. The second, as can be inferred, is a meter of multi-core performance. In every case, single core performance is dismal, but multi-core performance is significantly and systematically higher, as is to be expected from enterprise server equipment.
GB3 can be run in advanced mode, initializing either 32-bit or 64-bit tests from the command line which also makes it an ideal tool. Currently, several scripts are in place that run systematic benchmarks from time to time on the cluster to ensure continued machine performance as development wears on.
NOTE: While GB3 is not entirely open source, since it is purely a diagnostic and not integral to the engineered portions of the project, this detail was deemed to be acceptable.
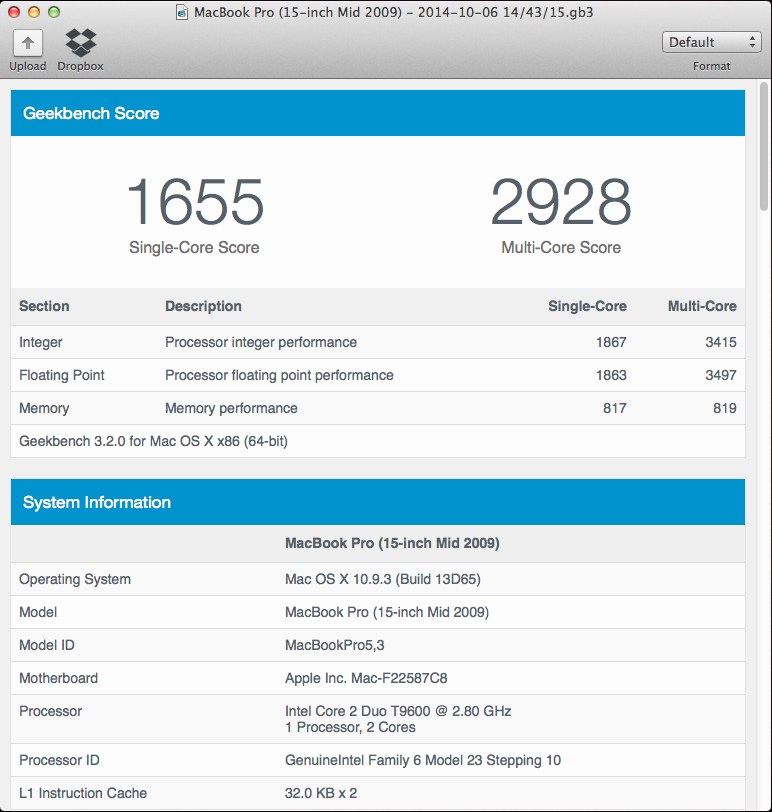
GB3 stores all information in the cloud through their unique web dashboard which means that no local storage is required unless a backup is decided. All of the final statistics will be downloaded and hosted in the final repository website upon completion of the thesis to preserve the computational requirements of the project.
Overall Benchmarking Results
Using a combination of the two final testing methods, comprehensive statistics are now able to be extracted from the cluster at any given time. The resultant information can be compiled into concrete statistics that display the overall power and comparative computational potential of each machine.
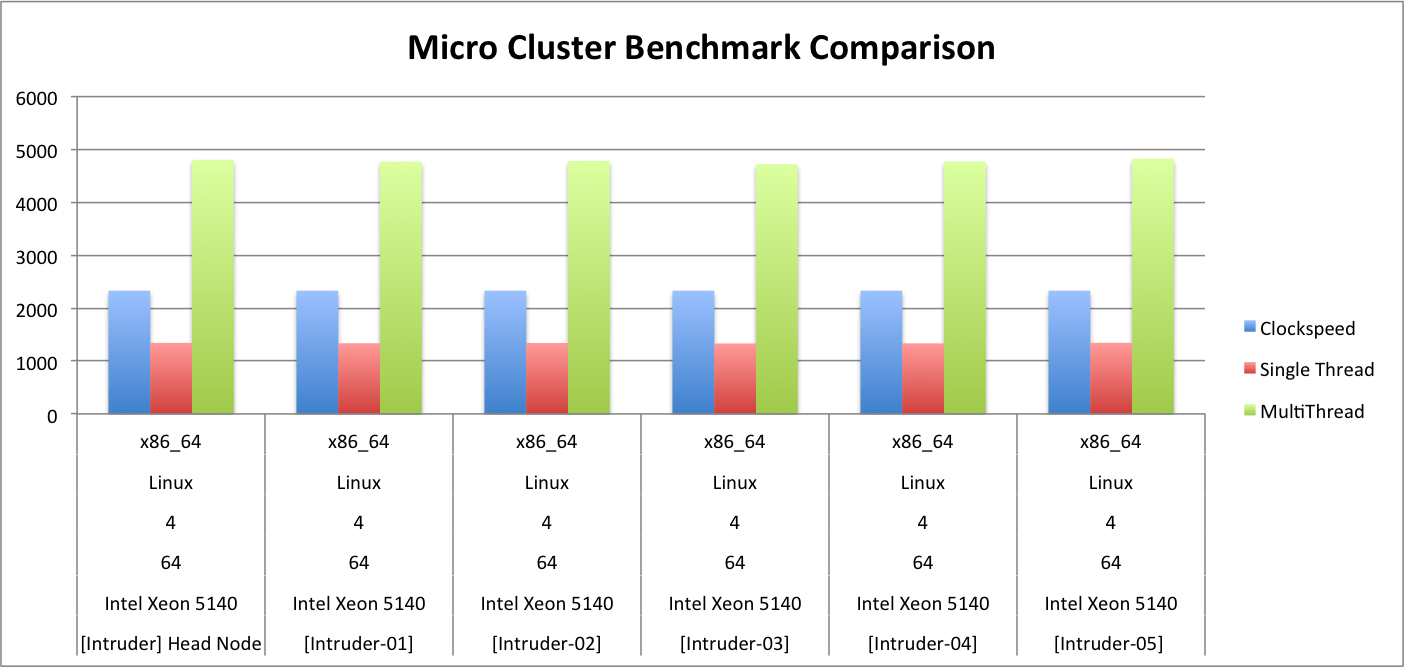
For instance, the above figure is an aggregate view of the processor clock speed, single thread performance and multi-core performance results for each server in the Intruder micro-cluster. All of the information is pulled from the unique Geekbench web register and simply inserted into Microsoft Excel to generate simple, elegant plots. It will later be seen how this information can be used by another service, Zabbix, although it is more automated and less useful for a la carte statistical analysis.
Software Virtualization
From time to time, it becomes an outright necessity to begin to virtualize a variety of different machines rather than run dedicated operating systems on every single node in the cluster.

This is especially the case in massive, less efficient machines, such as the Crawler and Whisper class compute nodes. These machines have such hefty CPU and RAM quantities that no specific image operation is stiff enough to require all resources from the machine. Thus, as a result, it is more efficient to virtualize several nodes on a single compute machine to take advantage of all available resources. Per the current engineering spec, this allows up to 5x in performance, but will be covered later in detail. Currently, VMWare Workstation and ESXi are used to convert running hosts into VM hosts, or to stand up bare metal hypervisors.
It was decided to use virtual machines during the spring semester phase in order to boost efficiency without increasing overhead cost, as well as replicating a more enterprise friendly solution. Few enterprise datacenters operate without the use of virtualization and hypervisors and in an effort to cater more directly to these environments, virtualization was brought to life.