- The Cerberus Project
- Introduction
- 1. Chapter 0 - Pitch and Abstract
- 2. Chapter 1 - Pitch and Summer Work
- 3. Chapter 2 - Fall 2014 Work
- 4. Chapter 3 - Spring 2015 Work
- 5. Chapter 4 - Architecture Software, Dependencies and Provisioning
- 6. Chapter 5 - Current Hardware Configurations
- 7. Chapter 6 - Monitoring the Cluster
- 8. Chapter 7 - Current Limitations of the Project
- 9. Chapter 8 - Utilizing the Cerberus Program
- 10. Chapter 9 - Performance of the Project
- 11. Chapter 10 - Final Results and Special Thanks
Chapter 5:
Current Hardware Configurations
Sparing the nitty gritty engineering documents that are contained in the internal documentation, this is a comprehensive list of the hardware contained in the presentation ready server rack. Although the generated software is built to be run independently on a linux cluster, there is necessary benchmarking and a token installation is integral to have. While software development could be executed on a single machine or a single unit cluster, the goal of the project is to take advantage of clustering and determine the necessary quantity of servers required to process images in the correct time frame. Carrying from Fall to Intersession, a significant portion of computers and servers have been acquired and configured to join the computational cluster.
Currently, as there are a significant amount of nodes under the project umbrella, a required naming convention was implemented. Due to family history in the armed services, most notably the United States Naval Service (NAVY), aircraft names common to the Navy were chosen to represent each server. These units, as they are introduced, will be referenced by these names in order to keep order. Notice that this following graph only displays the physical nodes in the cluster rack, to promote simplicity for the time being.
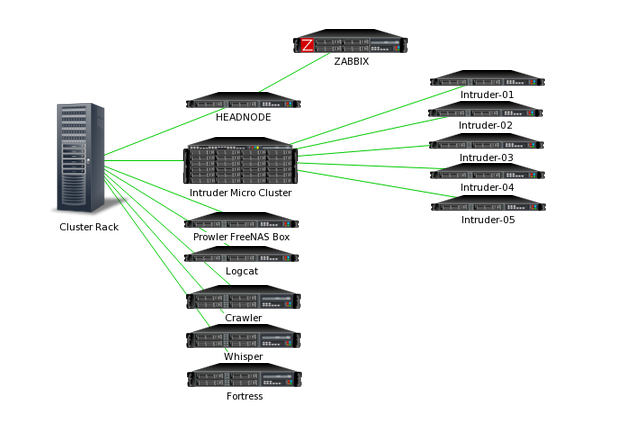
The Computational Cluster - Cerberus
Of the wide variety of machines used in the project, the most important, by far, is the physical computational cluster. Branded Cerberus, the cluster exists under three premises that defines the architecture of the cluster.
Cerberus, the fabled three headed beast in old world mythology, lived as a massive three headed beast. The cluster was labeled Cerberus based on the engineering philosophy that governed its inception. Although the cluster contains a significant quantity of machines, each of these fits into a very selective category, deemed a 'head'. The first category, the head node of the system is the intelligent head. The second category, the massive computational cluster nodes lives under the powerful head. The third, agile head is comprised of the high velocity, high I/O storage computers.

Agile Nodes
The first head of the system manages all of the high I/O data transfers of the system. Since 4K cinema footage takes up a significant amount of disk storage, each of these units manages a comparable quantity of redundant drive storage. These drives are standard, enterprise grade 7200rpm hard drives. configured in RAID storage setups. RAID stands for Redundant Array of Inexpensive Disks and is implemented widely in industry. These units also possess significant networking potential which allows the highest quantity of data to pass through the network to the required compute nodes for processing. A single Agile node is implemented, with two waiting in backup. As data is copied to initial staging node, it is also copied in parallel to the other two units in case of a primary Agile node failure.
The primary unit overseeing this operation is tagged Prowler, derived from the Northrop Grumman EA-6B Prowler, which is derived from the A-6 Intruder skeleton. This unit hosts 4x2TB Western Digital Enterprise Caviar Red Drives, which are installed with RAID 6 redundancy. This allows drives within the array to fail without causing catastrophic failure to occur. This also limits any cause of overarching node failure to be limited to the server itself, not just internal drive failure. The operating system on this node is also Linux based, although not of the CentOS kernel variety. Instead, and this is the only deviation from CentOS in the project, Prowler category nodes implement the FreeBSD based FreeNAS operating system.

FreeNAS is a custom distribution of the popular FreeBSD linux operating system. FreeNAS is tooled specifically to be a simple, enterprise ready NAS (Network Attached Storage) provider. FreeNAS allows for encryption, access privileges, file sharing and a wide range of additional, advanced administration features that make it ideal to the project. NFS (network file system) will be implemented across the Prowler node which allows for fast, Linux-friendly file sharing across the network between nodes. FreeNAS runs from an external storage medium, freeing up all housed drives for storage capacity increases. This can be accomplished by running the OS from a USB drive, living from any USB port on the server.
FreeNAS also allows the ability for select software packages or additional scripts to be run from quarantined software-based facilities known as jails. Some services are housed here, but all integral operations are coordinated from the head node which communicates directly with the server over SSH and the network. (Covered later.)
Powerful Nodes
Powerful nodes are also commonly known as compute nodes in the field of cluster computing. These nodes are managed from a centralized head node and are tasked only with the responsibility to crunch information based on their massive computational capacity. As a result of the disparity in the current cluster, there are two classes of compute nodes being utilized.
Flying Fortress Sub-class
Flying Fortress, or Fortress nodes, for short are massively powerful compute nodes that take their name from the B42 Flying Fortress bomber used in World War II. Managed remotely, they are tasked with the most intensive processing tasks. These units contain AMD enterprise grade Opteron processors, each with 8 CPU cores clocked near 3GHz. In addition, they are installed with 128GB of RAM apiece, which makes them the most RAM heavy machines in the cluster. Excessive quantities of RAM allows the compute node to work entirely from shared memory, accelerating the speed of computations to be bottlenecked only by the CPU and network. Fortress nodes are implementing 64-bit CentOS 6.6 operating systems that have been provisioned remotely, running from a small, internal 15Krpm hard drive. This combination of features adds up to a massively powerful machine, to be used for inline transcoding of the final data stream. Two of these units comprise the Fortress category of nodes.
As of the spring semester, it was decided to implement hypervisors on the Fortress style nodes to improve overall system performance. This allows multiple virtualized guest CentOS nodes to be run from each host, effectively allowing 100% of resources to be utilized.
Intruder Sub-class
Intruder nodes are also based off of the A-6 Intruder class plane that contributes to the Navy's aerial fleet. The Intruder fleet is comprised of 5 identical units acquired as a result of RIT's Computer Engineering department. These nodes make up the lions share of the processing power brawn, although they pack less power per unit than the Fortress class of compute power nodes. Coupled together, working in tandem, these units will also take direction from the head node to process cinema frames in parallel manner. These units also take advantage of internal 15Krpm hard drives to run the implemented CentOS 6.5/6.6 operating system. These units harness the power of dual, Intel Xeon Dual Core processors and 10GB of system RAM. This combination also allows each unit to work solely from shared memory, which maximizes throughput to be limited only by external factors that cannot be improved.
Intelligent Nodes
Intelligent nodes also refers to the presence of a singular head node. This node is entirely responsible for managing and direction the operations and responsibilities of every node in the cluster. Two intelligent nodes currently exist, both as identical clones. These machines are also Intruder class nodes that have been adapted to serve as head nodes. Serving as a head node merely implies the installation of additional software, to be covered later. This node is arguably the most important node, as it is in control of all operations running the project. For this very reason, in the interest of risk management and data security, a second, cloned node exists. Every day at midnight, this secondary node syncs with the primary head node to ensure they are identical. The head node also takes advantage of CentOS 6.5/6/6 in order to ensure compatibility with all other nodes in production use.
Other Computing Assets
While this setup of 10 nodes exists as the current Cerberus cluster, there are a variety of other computing assets. In total, this covers:
- 5 Laptop Machines
- 10 Virtual Machines
- 5 Desktop Machines
- Additional Server Units
Laptops and Desktops
Laptops are entirely used for mobile development and the ability to monitor the cluster from abroad, either on campus or off.
The same goes for all three desktop machines, which server as satellite machines. These are handy for heavy development and allow for more efficient working given their workstation components and assortment of screens.
Virtual Machine - Development Environment
The first Virtual Machine was actually a collection of specific virtual operating systems being run off of a rack server utilizing ESXi. ESXi allows for base level OS virtualization and was most heavily utilized in the early stages of the project to choose a node OS. Through this process, Ubuntu, RHEL, Debian, Fedora, OpenSUSE, Cent and ARCH linux were tested. Of these, CentOS was the obvious victor since it is the currently implemented OS on the cluster. This unit still runs continuously and is often used to troubleshoot issues across OS's, especially when package dependencies are found to be in error.
Koding
Koding is an interesting web-based IDE (Integrated Developing Environment) that runs a virtualized OS dashboard from an Amazon AWS based EC2 server instance in the cloud. This IDE also allows for some local storage which is helpful for mobile development or testing features from abroad without having to physically work on the cluster nodes, a development server or spin up an additional test VM.
Koding is being used under its free license, which grants 1-2GB of local storage and a 60 minute development window. If the session is left unattended for more than 60 minutes, the web initialized session of the active VM spins down in order to allow other users more active sessions. This specific session syncs with the all of the code repositories hosted (to be covered later) so that it is always up to date with current versions of all available code whenever it is initialized, regardless of how long the session has been dormant.
Desktop Machines
Often times, heavy development is required to be executed from a workstation style desktop machine. All of these are managed from a central repository that syncs code between nodes. The benefit to all of the workstations contained here is massively powerful local hardware and multi monitor setups. The most powerful desktop takes advantage of 4 monitors which makes development easy.
There are a variety of other, additional machines, referred to as satellite nodes that are also used. These come in the form of surplus test nodes or desktop machines that were used for benchmarking and added to the cluster in case of massive and excessive computational power requests.
Additional Server Units
There are a collection of additional server units that are used in the development of the thesis, but these are mostly for redundant security purposes and repository hosting. Vital code repositories are stored on public facing servers that allow RPM and Yum to draw from their resources. None of these are integral to the internal engineering of the project so these resources will only be discussed as needed.
University Machines
There are a wide variety of machines that can be used for student use at RIT. Most of these machines are embodied in RIT's Center for Imaging Science. These are powerful desktop machines that are for student academic use. Currently, they are a part of the cluster but listed as satellite nodes, to be used only if extra horsepower is required. These nodes are physically located away from the cluster and therefore are more subject to ping and latency issues between the main cluster and the satellite nodes. These are more useful to research at this point although it is useful to have extra resources if more are required.
Monitoring Utilities
There are several intensive monitoring services that are required in order to monitor the overall health and consistent performance of the cluster and all attached services. In addition to this, security monitoring is also intrinsic to the health of the cluster and attached. This will be covered in the next chapter.